HealthSurgeon - Healthy Living and Fitness - Purium Coupon
Primary Navigation Menu
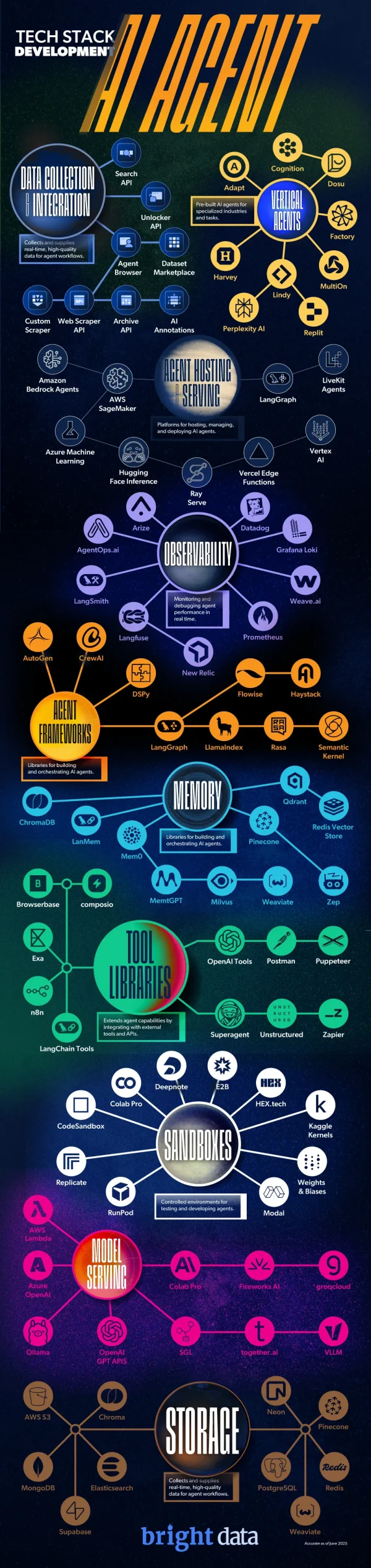
How the AI Tech Stack Powers the Next Generation of AI Agents
The next generation of automation is here – many workers are now adopting the use of AI agents into their workflows. They can have their AI agent act as an independent assistant and perform a huge range of tasks, including everything from conducting research to managing entire projects. However, while the end user just sees the output they need, there is a lot going on behind the scenes. Every agent is relying on a carefully constructed AI agent tech stack, which is many layers of tools that work together to enable the agents to reason, act, and adapt with independence.
The most important piece of the tech stack puzzle is the data that the AI agent is being trained on. Without being properly fed real time data from the public web, the AI agent won’t be able to access the most up-to-date and helpful information. There are some specific APIs that make this process smoother. For instance, Search API helps surface relevant web content in real time. Web Scraper API is another tool that performs a similar function – it extracts structured data from over 120,000 websites immediately. Productivity can improve exponentially with the help of this infrastructure that lets AI teams plug into the public web with precision.
Data serves as the foundation for all of the other tools and systems to layer on top of. An example of another layer is memory systems, which allow agents to retain context, instead of forcing a user to enter their information again each time they want to use their agent. Sandboxes provide isolated environments for agents to write and run code to test out which version works best. Observability tools help developers monitor the performance of the AI agents and build an understanding of their decision logic. All of these layers of tools play their own huge role in an AI agent’s performance.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.